联系作者

# 计算机网络简史
学计算机一定要注重人文知识,人文知识最终影响你的判断力,以及你对未来的认知,有这样一部分功底,你就比别人看的多。
# 1. ARPANET 的发展
ARPA那时候不叫计算机网路,有一个叫做数据网的方向,黄色部分连接的美国的地图。
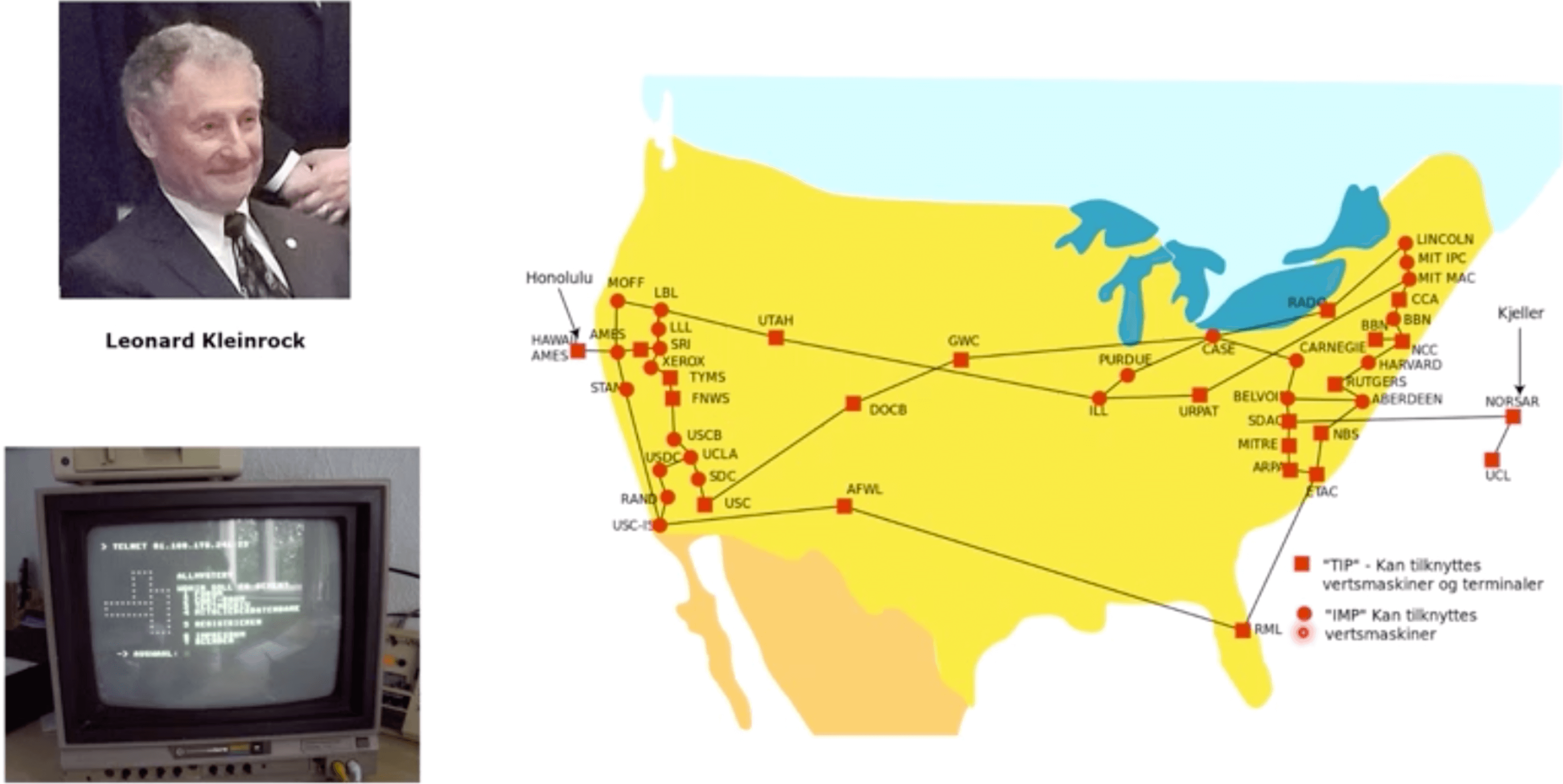
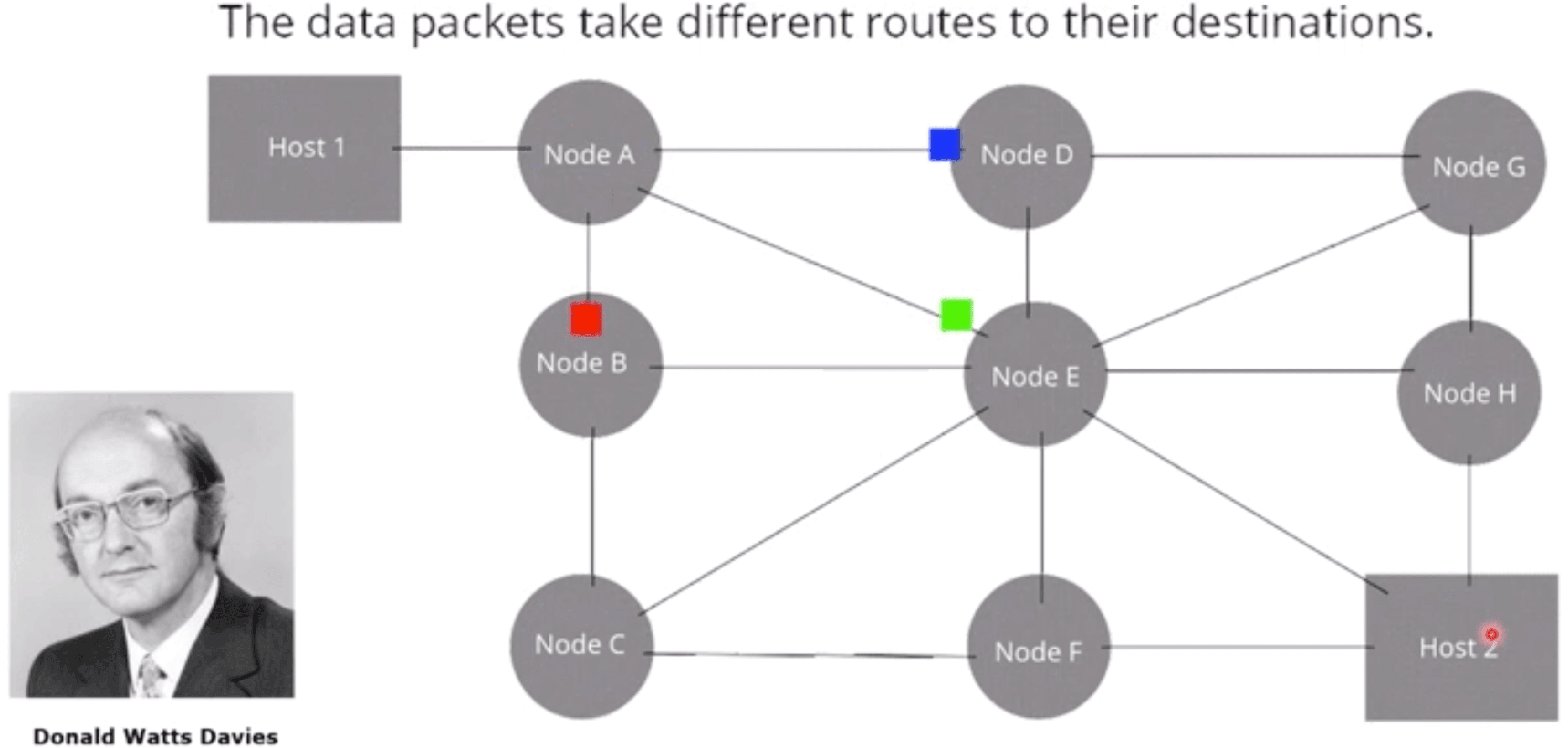
# 1965-packet switching(分包交换)
The data packets take different routes to their destinations
# 1969
- 第一个RFC(开始通过APPANET发布) R:request F:from C:comment 就是写一篇文章,别人可以对你的文章进行评论
- 第一个接口处理信息单元(interface Message Processor)
- 互联网internet
# 1970s
- 1971- 第一个email(ARPANET)
- 1971- ALOHAnet:第一个wifi(Wireless Fidelity)
- 1973- Ethernet
- 1973- SATNET
- 1973- IP电话/互联网电话(VOIP),第一个给用户使用的电话在1995
- 1974- 路由器(施乐 Xerox)
- 1976- 第一个IP路由器,但是被称做网关(Gateway)
- 1978- Bob Kahn发明了TCP/IP协议
# 2. 逐渐成形的互联网
# 1980s
- 1981- internet protocal Version 4 ,RCF 791
- 1981- BITNet
- 1981- CSNet
- 1983- ARPANET迁移到TCP/IP协议
- 1983- DNS(Domain Name System)
- 1986- BITNet II
- 1988- WaveLan(Wi-Fi)
- 1988- Packet filter wall (第一个防火墙Paper)
- 1988- APAPNet 升级为T1主干网络
# 1990s
- 1990 - 第一个交换机(Kalpana)
- 1996 - IPv6
- 1997 - 802.11 wifi 标准(2mbps)
- 1999 - 802.1a 标准(5GHz 25mbps)
- 1999 - 802.11b 标准(11mbps)
- 1999 - WEP加密协议(RC4+CRC-32)
# 2000s
| 年份 | 事件 |
|---|---|
| 2003 | 801.11g(54mbps) |
| 2003 | WPA加密协议 |
| 2003 | WPA2加密协议 |
| 2008 | 4G标准(100Mbps) |
| 2009 | 802.11n标准(600Mbps) |
# 1.1 OSI七层模型
# 1.1.1 OSI七层模型
- 开放式系统互联网模型
- 世界范围内的网络标准概念模型
- OSI的努力让互联网协议组件走向标准化
# 应用层
提供高级API
- 定义了网络主机提供的方法和接口(业务协议、高级协议)
- 往往直接对应用户行为
- 例如:HTTP、FTP、SMTP等
# 展示层
- 也被称做语法层
- 将Application layer中的数据转化为传输格式,保留语义(如:序列化、加密解密、字符串编码解码等)
- 确保数据发送取出后可以被接受者理解
# 会话层
- 提供管理会话的方法(Open/Close/ReOpen/检查状态等)
- 提供对底层连接的断断续续的隐藏;甚至对多种底层流的隐藏(提供数据同步点)
# 传输层
提供主机到主机(host-to-host)的数据通信能力
- 建立连接保证数据封包发送、接受到的顺序一致
- 提供可靠性(发送者知道数据有没有被完整送达)
- 提供流控制(发送者和接受者同步速率)
- 提供多路复用(多种信号复用一个信道)
# 网络层
提供数据在逻辑单元(例如IP地址)之间的传递能力
- 路由:决定数据的下一站在哪里
- 寻址:为数据封包增加头信息(地址等)
# 数据链路层
提供数据在设备和设备之间的传输能力
流控制 :发送者接受者之间同步数据是收发速度和数据量
错误控制:检测数据有没有出错,并重发出错的数据
# 物理层
定义底层一个位(bit)的数据如何让变成物理信号
将数据链路层发生的数据传递行为转化成为物理设备识别的信号
封装了大量底层物理设备的能力
# 1.2 TCP/IP 协议和互联网协议群
今天使用最多的协议群
# 1.2.1 TCP/IP协议群简介
# 互联网协议群
- 类似OSI模型,一种网络协议的概念模型
它对OSI七层模型做了简化,把OSI的应用层、展示层、会话层简化成了应用层
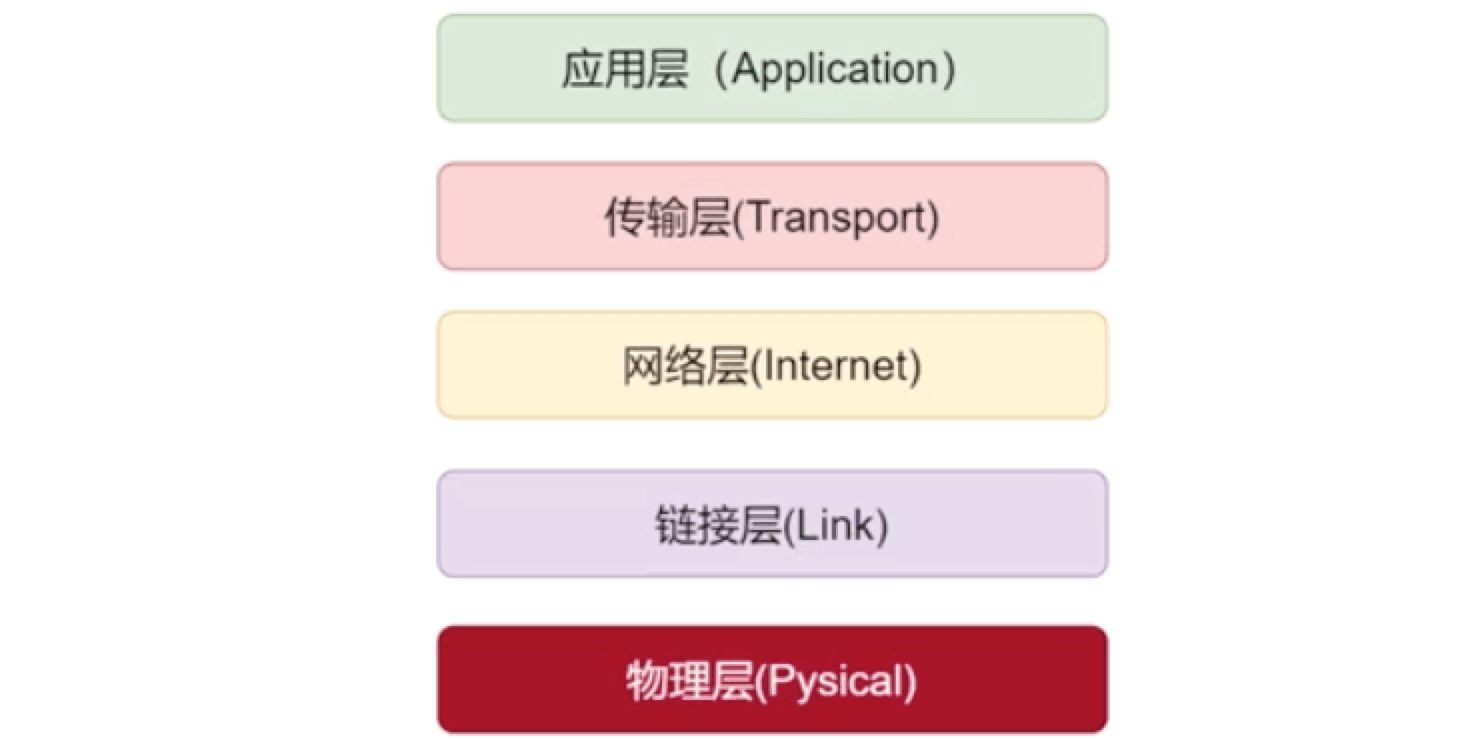
- 应用层
- 提供应用间通信能力(HTTP协议)
- 传输层
- 提供主机到主机的通信能力(TCP/UDP协议)
- 网络层
- 提供地址到地址的通信能力(form:12.3.41.1->to :9.1.2.12)
- 链路层
- 提供设备到设备的通信能力(设备1->设备2)
- 物理层
- 光电信号的传输
# 1.2.2 TCP 三次握手(Three-Way Handshake)
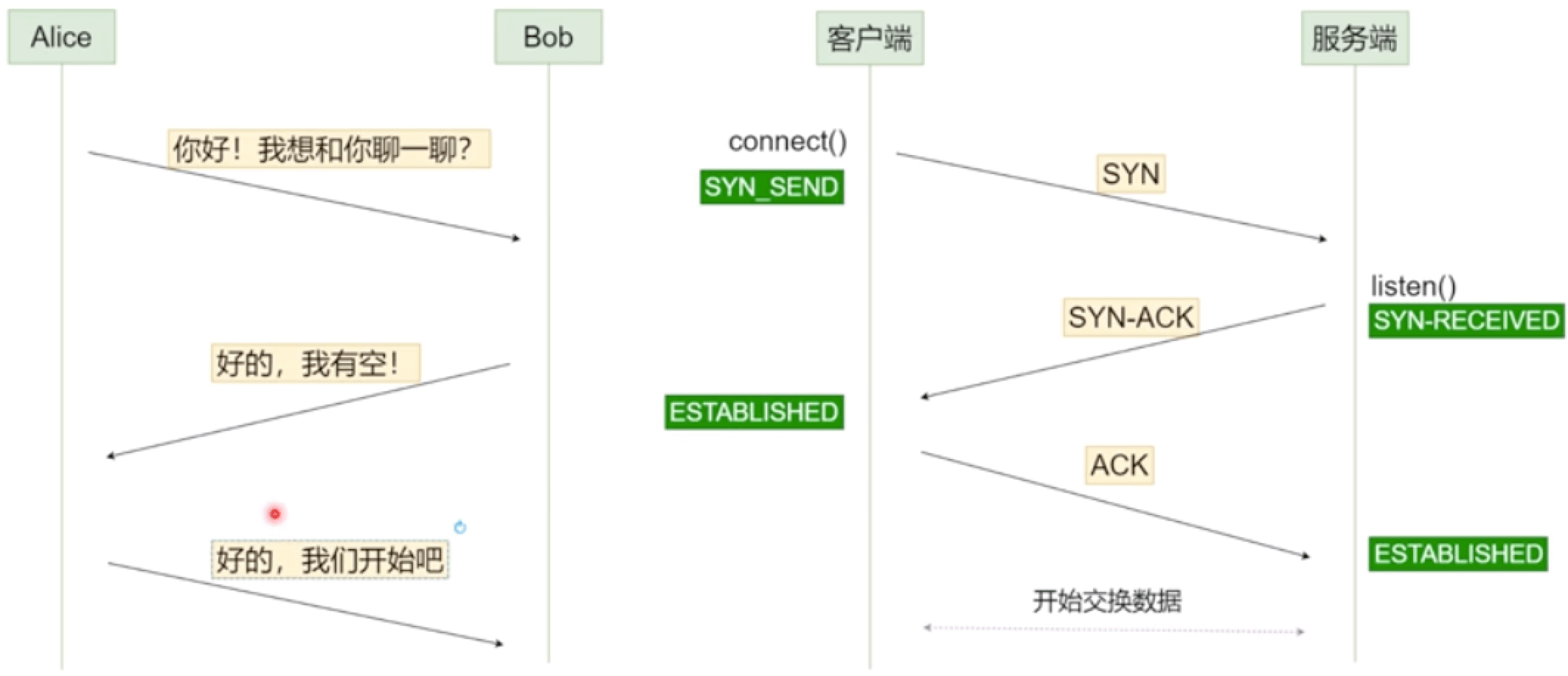
TCP三次握手用于在客户端和服务器之间建立可靠的连接。具体步骤如下:
1.SYN(同步报文): 客户端:向服务器发送一个TCP报文,SYN标志位设为1,并包含一个初始序列号(Sequence Number, seq)。此报文表示客户端请求建立连接。 报文示例:SYN(seq=x)。
2.SYN-ACK(同步-确认报文): 服务器:收到SYN报文后,回复一个SYN-ACK报文,SYN和ACK标志位均设为1。服务器的SYN报文包含其自己的初始序列号(seq=y),ACK报文的确认号(Acknowledgment Number, ack)设为客户端的序列号加1,即ack=x+1。 报文示例:SYN-ACK(seq=y, ack=x+1)。
3.ACK(确认报文): 客户端:收到服务器的SYN-ACK报文后,发送一个ACK报文,ACK标志位设为1,确认号设为服务器的序列号加1,即ack=y+1。至此,连接建立成功,可以开始数据传输。 报文示例:ACK(ack=y+1)
# 1.2.3 TCP/IP协议的消息顺序处理方法
- 消息的绝对顺序用(SEQ,ACK)这一对元组描述
- SEQ(Sequence):这个消息发送前一共发送了多少字节
- ACK (Acknowledge):这个消息发送前一共收到了多少字节
# 1.2.4 TCP 四次挥手(Four-Way Handshake)
TCP四次挥手用于断开客户端和服务器之间的连接。具体步骤如下:
1.FIN(终止报文): 客户端:发送一个FIN报文,FIN标志位设为1,表示客户端要终止连接。 报文示例:FIN(seq=u)。
2.ACK(确认报文): 服务器:收到FIN报文后,回复一个ACK报文,确认号设为客户端的序列号加1,即ack=u+1。 报文示例:ACK(ack=u+1)。
3.FIN(终止报文): 服务器:准备好终止连接后,发送一个FIN报文,FIN标志位设为1,并包含其自己的序列号(seq=v)。 报文示例:FIN(seq=v)。
4.ACK(确认报文): 客户端:收到服务器的FIN报文后,发送一个ACK报文,确认号设为服务器的序列号加1,即ack=v+1。至此,连接彻底断开。 报文示例:ACK(ack=v+1)。
# 1.2.5 详细说明
三次握手的目的:
TIP
确认连接双方都有接收和发送数据的能力。
同步序列号,以便双方能够正确重组数据包。
防止旧的重复连接请求干扰新的连接。
四次挥手的步骤原因:
TIP
客户端发送FIN报文:表明客户端已无数据要发送,但仍能接收数据。
服务器发送ACK报文:确认收到客户端的FIN报文。
服务器发送FIN报文:在处理完所有数据后,通知客户端可以断开连接。
客户端发送ACK报文:确认收到服务器的FIN报文后,连接正式关闭。
这些步骤确保了在断开连接时,双方都能处理完所有的数据传输,不会有数据丢失或中断。
# 1.3 DNS与CDN
# 1.3.1 DNS的基础知识
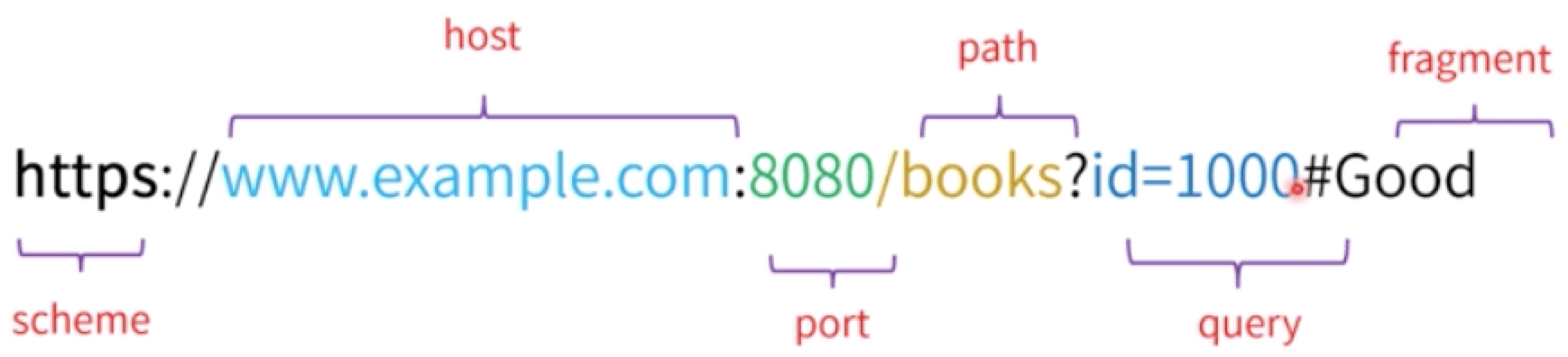
# 统一资源定位符(URL)
- 也被称作(网址),用于定位互联网上的资源
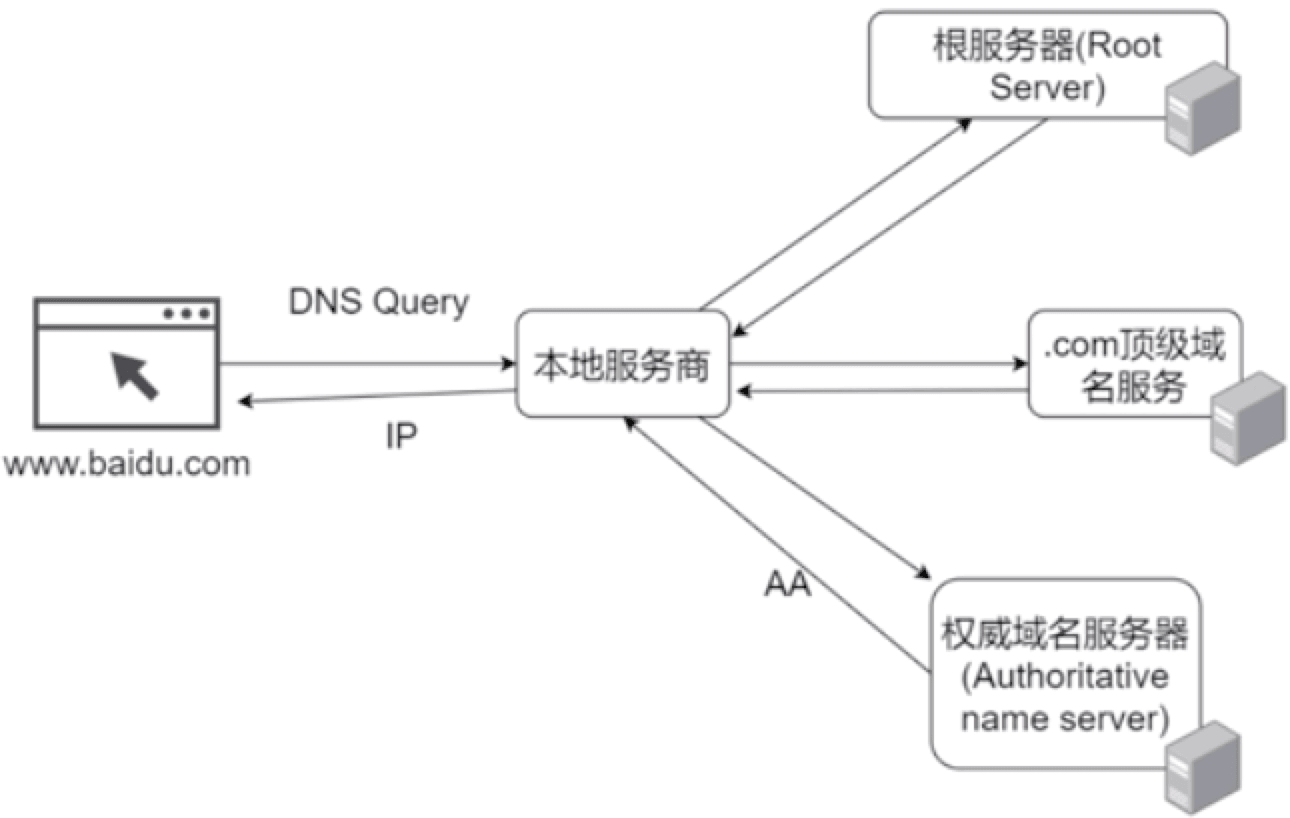
# DNS Query过程
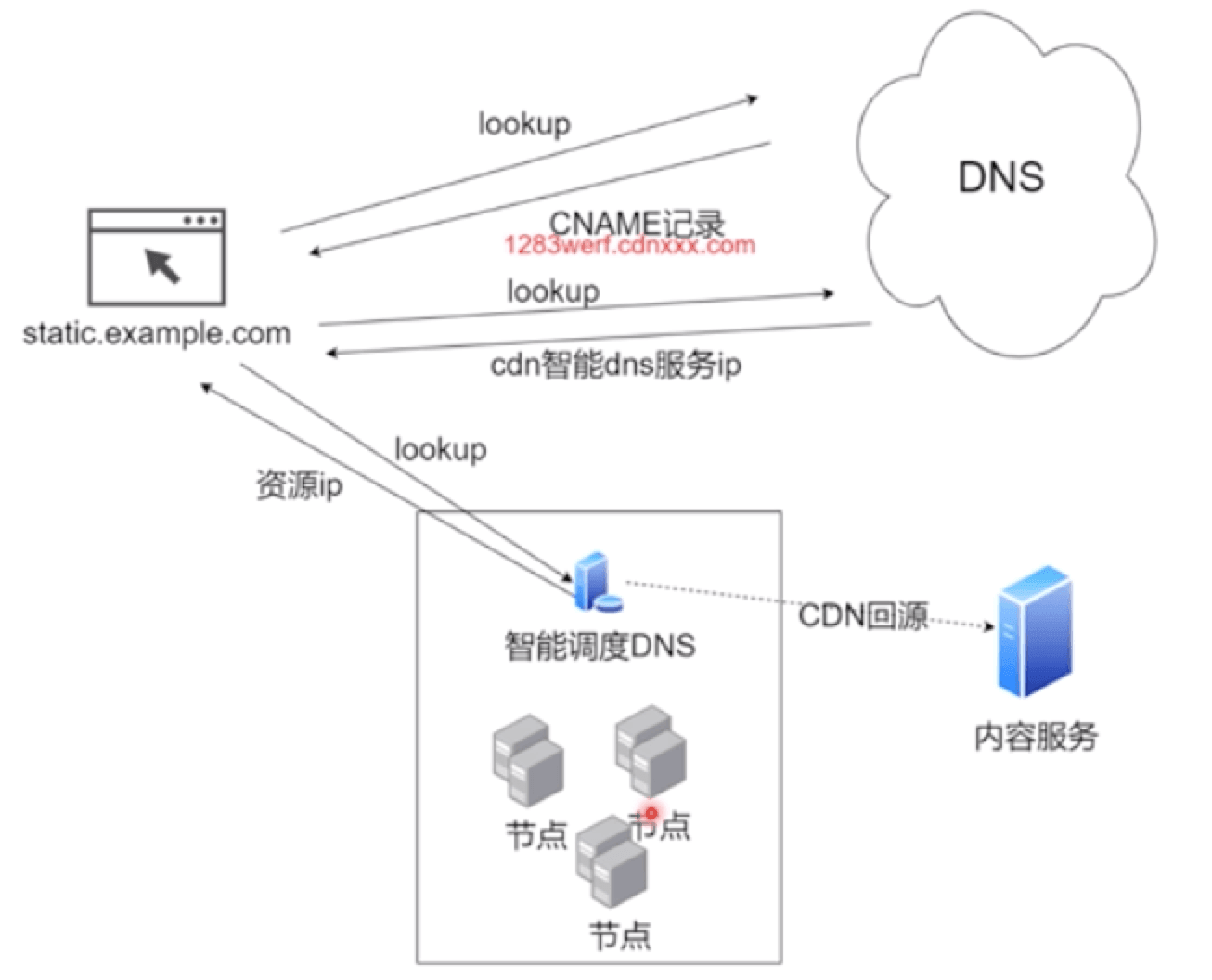
# 1.3.2 CDN 实现原理
cdn用于存变化不大的文件
# CDN云测工具
# 1.4 HTTP入门和基础工具链
# 蒂姆.伯纳斯-李
- 英国著名科学家(1955-)
- 万维网(1990年HTTP协议)
- 创办MIT人工智能实验室
# 1.4.1 HTTP协议
超文本传输协议
超是一个形容词,形容这个文本很厉害,这个协议是挂在tcp上实现的,开始设计就是客户端和服务端通信的,它提供了一种标准就是中间可以传文本, 因为传二进制太复杂了,传文本大家都看的懂,容易推广就容易普及。
处理客户端和服务端之间的通信
http请求/http返回
网页/json/xml/提交表单
# 纯文本+无状态(stateless)
- 应用层协议(下面可以是TCP/IP)
- 信息纯文本传输
- 无状态
- 每次请求独立
- 请求间不影响
- 浏览器提供了手段维护状态(Cookie,session,*Storage等)
# HTTP历史
- 1991 HTTP 0.9
- 1996 HTTP 1.0
- 1999 HTTP 1.1
- 2015 HTTP 2.0
# 设计的基础因素
- 带宽
- 基础网络(线路、设备等)
- 延迟
- 浏览器
- DNS查询
- 建立连接(TCP三次握手)
# 设计考虑因素-缓存与带宽优化
缓存
- (http1.0)提供缓存机制如IF-Modified-Since等基础缓存控制策略
- (http1.1)提供E-Tag等高级缓存策略
带宽优化
- (http 1.1)利用range头获取文件的某个部分
- (http 1.1)利用长连接让多个请求在一个TCP连接上排队 如果每一个请求都建立一个TCP,这样是非常浪费带宽的,如果所有请求都复用一个tcp,那么这样省去了一些tcp握手的开销。
- (http 2.0)利用多路复用技术同时传输多个请求 进一步节省带宽
# 设计考虑因素-压缩/安全性
压缩
- 主流web服务器如nginx/express等都提供gzip压缩功能
- (http2.0)采用二进制传输,头部使用HPACK算法压缩
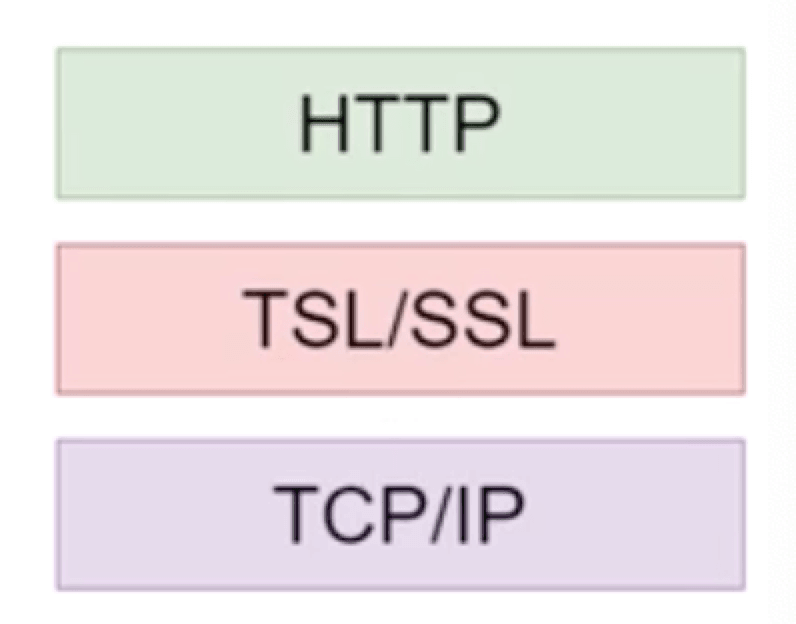
HTTPS
- 在HTTP和TCP/IP之间增加TSL/SSL层
- 数据传输加密(非对称+对称加密)
# 1.4.2 HTTPS
- 安全超文本传输协议(Hyper Text Transfer Protocol Secure)
- 数据加密传输
- 防止各种攻击手段(信息泄露、篡改等)
- SSL/TSL(Secure Socket Layer/Transport Layer Secure)
- SSL-安全套接层
- TSL-传输层安全性协议
- 需要在客户端安装证书
# 1.4.3 Node.js实战http请求
# 🍅 Header和Body(实战)
- http协议是一个文本传输协议,传输内容是人类可读的文本,大体分成2部分:
- 请求头(header)/返回头
- 消息体Body
- 观察node实现http的基础协议
const net = require('net')
const response = `
HTTP/1.1 200 ok
Data: Tue,30 Jun 2020 01:00:00 GMT
Content-Type: text/plain
Connection: Closed
// 上面是描述,下面设计文本内容
Hello word
`
const server= net.createServer(socket=>{
socket.end(response)
})
server.listen(80,(err)=>{
console.log('err',err);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
我们请求一下http://localhost/
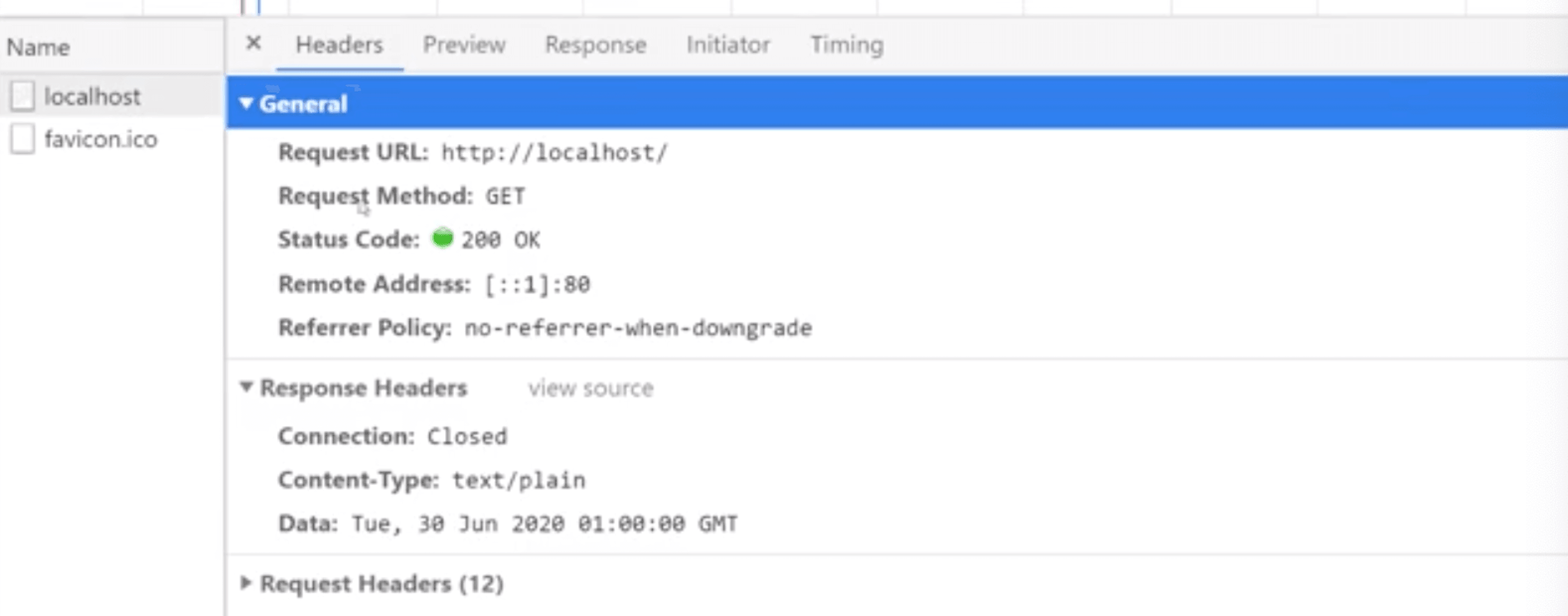
从上图可以看出respoons header是我们添加进去的,request header是浏览器帮我们添加进去的
# 1.4.3 基础工具链
- Chrome
- Google 开发的免费浏览器
- Chrome 开发者拥有强大的调试能力
- cURL
- 传输一个URL(和服务端交互的工具)
- url:网址(Uniform Resource Locator)
- 支持多种协议(HTTP/HTTPS/FTP/FTPS/SCP/SFTP/DICT/TELNET)
curl www.baidu.com # 返回百度首页的内容,跟浏览器是一样的,会少一些响应头
curl -I www.baidu.com # 返回协议头部
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Sun, 14 Feb 2021 09:12:18 GMT
Etag: "575e1f59-115"
Last-Modified: Mon, 13 Jun 2016 02:50:01 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
2
3
4
5
6
7
8
9
10
11
12
13
14
- fetch
- 在网络上获取数据的标准接口
- 提供对请求/返回对象(标准的Promise接口)
- 提供自定义header能力
- 提供跨域能力
浏览器上可以直接请求 fetch("/")
- postMan
- 协作的API开发工具
经常用的场景是服务端工程师把一些复杂的请求参数配置好,通过postman可以分享出来给前端工程师
- whistle
whistle是一个抓包的工具,也叫网络调试工具,它能看到这些分包,可以在http协议上修改一些参数。
- 跨平台网络调试工具
- 需要SwitchOmega插件
- node.js 开发
- 支持抓包 、重放、替换、修改等
npm i whistle -g # 下载,mac电脑:sudo npm i whistle -g
whistle start # 启动
http://localhost:8899/ # 浏览器查看
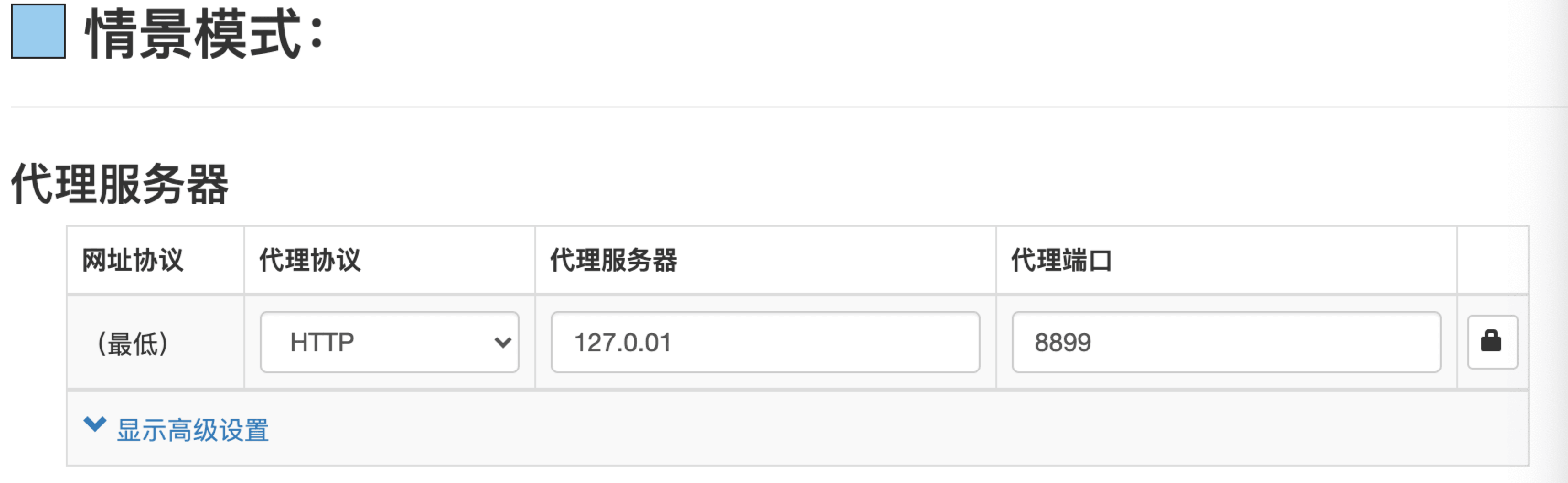
SwitchOmega # 谷歌代理插件,可以配置127.0.0.1:8899的服务上
2
3
4
# 🍅 谷歌代理插件SwitchOmega,配置代理服务器127.0.0.1:8899的服务
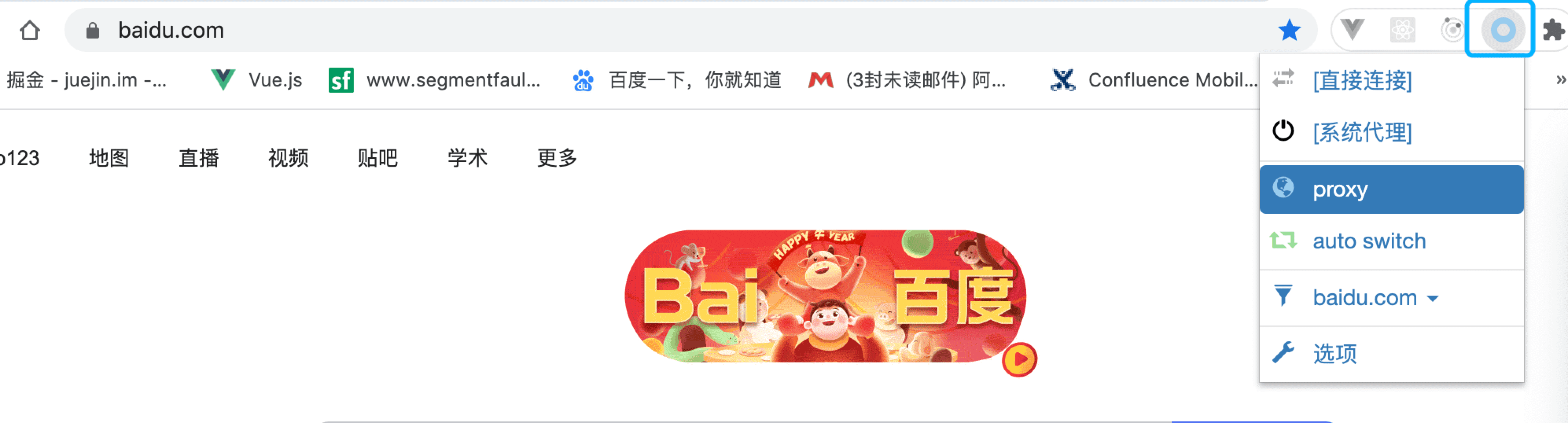
# 🍅 示例:以代理百度为例
在想要代理的网址上选择proxy
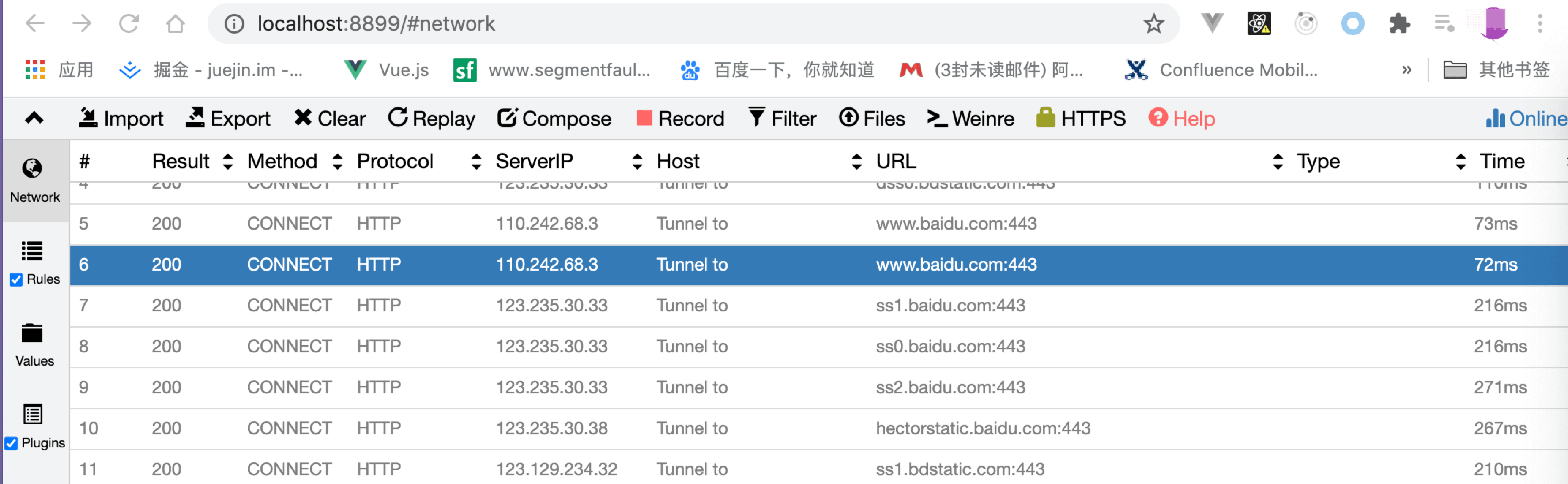
查看代理信息
# 小结
简单比效率更重要(java/HTTP)等
# 1.5 HTTP协议详情讲解
# 1.5.1 HTTP协议内容和方法
# 🍅 HTTP常见的请求头

# 🍅 HTTP常见的返回头
HTTP/1.1 201 Created # 协议版本、状态码
x-Powered-By: Express # X-Powered-By
Date:Sun,19 Jul 2020 14:01:51 GMT # 日期
Connection: keep-alive # Connection
Content-length: 0 # content-length
2
3
4
5
# 🍅 基本方法
- GET
- 从服务器获取资源
- HEAD
- HEAD和GET类似,只是服务器的响应中只返回头部(没有实体部分);在不获取资源情况下了解资源的状况
- POST
- 在服务器创建资源
- PUT
- 在服务器修改资源(幂等性),同一个url多次请求只修改一次
- DELETE
- 在服务器删除资源(幂等性),同一个url多次请求只删除一次
- OPTIONS
- 跨域时复杂请求
- 使用了 put/delete/connnect/trace/patch
- 人为设置了一些header字段
- content-type的值不属于:application/x-www-form-urlencoded、multipart/form-data、text/plain
- 跨域时复杂请求
- TRACE 用于显示调试信息
- 多数网站不支持,会泄露一些调试信息或者只有内部的时候才支持,它能帮助你追述整个http的链路,假如http发出去,它可能接收第一个不是网关; 它可能是代理服务器,再通过负载均衡才到达你真实的服务器,这里面有一定的路径,trace可以帮助我们请求http协议的网址时协议调试信息
- CONNECT
- 代理
- PATCH
- 对资源进行部分更新(极少用)
# 1.5.2 常见HTTP状态码
# 🍅 状态码
1.xx :提供信息
- 100 continue 主要用来提供信息的,这个100还有一点历史原因,现在带宽都比较大;有时候传输数据比较大 客户端询问一下服务端,服务端如果发送100continue,客户端继续向服务端传送,现在已经用的很少了。
- 101 切换协议(switch Protocol) 我们浏览器生态不光有http协议、websocket协议、还有一些视频流的一些协议;这些协议和http之间是怎么切换的,客户端请求服务端的时候,如果服务端需要切换协议,会返回101,告诉客户端切换协议
HTTP/1.1 101 Switching Protocols Upgrade:websocket Connection: Upgrade1
2
32XX:成功
- 200-ok
- 201- Created 已创建
- 202- Accepted 已接收
- 203- Non-Authoritative information 非权威内容
- 204- No Content 那样内容
- 205- Reset Content 重置内容
- 206- Partial Content 服务器下发了部分内容(range header) 注:多数服务端开发已经不遵循状态码
3XX:重定向
- 300- Multiple Choices 用户请求了多个选项的资源(返回选项列表)
- 301- Moved Permanently 永久转移 (如果以前是post、delete等方法,如果在303的情况都会变成get)
- 302- Found 资源被找到(以前是临时转移,现在被拆成了2个状态码303和307)
- 303- See Other 可以使用GET方法在另一个URL找到资源(不管以前使用什么方法跳转过来的,最终303都给跳转一个get方法)
- 304- Not Modified 没有修改(这个资源没有再请求一遍,现在很多web服务器,它在下发资源给浏览器的时候,它会把资源内容做一次计算,计算出一个唯一的哈希值,哈希值会作为target传下来,浏览器会对比这个target,target变化会再去请求一次,web服务器知道哪些资源有变化,它有些算法在里面,计算出有没有变化,没有变化会返回一个304,并不会返回真实的资源。)
- 305- Use Proxy需要代理
- 307- Temporary Redirect 临时重定向
- 308- Permanent Redirect 永久重定向 (如果是post请求,收到308后还是308请求)
收到服务端状态码,我们该怎么做?
这不是程序所决定的,它不是这个逻辑,因为整体设计是一个协议一个标准;在请求的时候我们能拿到状态码,即使返回了301我们都可以不用去跳转,反正你就不遵守协议,这无所谓,但是设计浏览器的人,他们都遵循这些协议,这些协议是一个标准,正常来说也要遵循这些协议;即使权利交到你手里 ,如果总是违反协议做事情,大家都乱了,大家要重新商议协议,沟通成本会增加。
🍅 面试解惑:301 vs 308
- 共同点
- 资源被永久移动到新的地址
- 差异
- 客户端收到308请求后,之前是什么method,那么之后也会沿用这个method(POST/GET/PUT)到新地 址
- 客户端收到301请求后,通常用户会向新地址发起GET请求
历史原因:最早的浏览器设计不是像今天这样用ajax请求去动态创建网页,过去网页是网页设计师写出来的,那时候主要的请求都是GET,最早定义规范的人,他也强调过301怎么去做,定义协议的人其实考虑到这个问题了,但是大家都没有遵守这个协议,一开始本来你给我POST,我给你POST ,只是网址变化一下,但都大家不理它,导致http1.1之后还有增加308这些头。
🍅 面试解惑:302/303/307
共同点
- 资源临时放到新地址(请不要缓存)
差异
- 302是http1.0提出的,最早叫做Moved Temporarily;很多浏览器实现的时候没有遵循标准,把所有请求都重定向到GET
- 1999年标准委员会增加了303和307,并将302重新定义为Found
- 303告诉客户端使用GET方法重定向资源
- 307告诉客户端使用原请求method重定向资源
4XX:客户端错误
- 400- Bad Request 请求格式错误
- 401- Unauthorized 没有授权
- 402- Payment Required 请先付费
- 403- Forbidden 禁止访问
- 404- Not Found 没有找到
- 405- Mehtod Not Allowed 方法不被允许
- 406- Not Acceptable 服务端可以提供的内容和客户端期待不一样
注:多数服务端开发已经不遵循状态码
5XX:服务端错误
- 500 - internal Server Error(内部服务器错误)
- 501 - Not implemented(没有实现)
- 502 - Bad Gateway(网管错误)
- 503 - Servive Unavailable(服务不可用)
- 504 - Gateway Timeout (网关超时)
- 505 - HTTP Version Not Supported(版本不支持)
注:多数服务端开发已经不遵循状态码
# 1.5.3 常见HTTP头
# 🍅 Content-Length
- 发送给接收者的Body内容长度(字节)
- 一个byte是8bit
- Utf-8编码的自渎1-4字节
# 🍅 User-Agent
- 帮助区分客户端特性的字符串
- 操作系统
- 浏览器
- 制造商(手机类型等)
- 内核类型
- 版本号......
# 🍅 Content-Type
- 帮助区分资源的媒体类型(Media Type/MIME Type)
- text/html
- text/css
- application/json
- image/jpeg
- ......
# 🍅 Origin
- 描述请求来源地址
- scheme://host:port
- 不含路径
- 可以是null
# 🍅 Accept
- 建议服务端返回何种媒体类型(MIME Type)
- */*代表所有类型(默认)
- 多个类型用逗号隔开例如:text/html,application/json
- Accept-Encoding:建议服务端发送哪种编码(压缩算法)
- deflate,gzip;q=1.0,*;q=0.5
- Accept-Language:建议服务端传递哪种语言
- Accept-Language:fr-CH,fr;q=0.9,en;q=0.8,de;q=0.7,*;q=0.5
# 🍅 Referer
- 告诉服务端打开当前页面的上一张页面的URL;如果是ajax请求,那么就告诉服务端发送请求的URL的是什么
- 非浏览器环境有时候不发送Referer(或者虚拟Referer,通常是爬虫)
- 常常用于用户行为分析
# 🍅 Connection
- 决定连接是否在当前事务完成后关闭
- Http1.0 默认是close
- Http1.1后默认是keep-alive
# 1.6 全栈角度看HTTP协议
# 1.6.1 解析Body和2xx状态码
# 🍅 实战-method和解析body
- 查询 GET /product
const express = require('express')
const app = express()
app.get('/product',(req,res)=>{
res.send('ok')
})
app.listen(3000,()=>{
console.log('启动成功');
})
2
3
4
5
6
7
8
9
- 新增 POST /product
const express = require('express')
const app = express()
app.post('/product',(req,res)=>{
const contentType = req.headers['content-type']
let requestText=""
// http请求基于tcp,tcp会把传的数据,分成一个个分包;并不是一次传过来的;req不仅是一个请求对象,也继承了流的性质
// 流代表了未来的数据,当数据来的时候把数据给装起来
req.on('data',(buffer)=>{
// utf-8 用1到4个字节描述一个字符,世界上有太多字符了,像a、b、c这样的一个字节就描述完了
console.log('buffer',buffer.length)
requestText += buffer.toString('utf-8')
})
req.on('end', ()=>{
console.log('contentType',contentType)
switch(contentType) {
case "application/json" :
// console.log('requestText',JSON.parse(requestText))
res.set('content-type','application/json')
res.status(201).send(JSON.stringify({success:'ok'}))
break
}
})
})
app.listen(3000,()=>{
console.log('启动成功');
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
在浏览器上请求一下fetch("/product",{method:"POST",headers:{'content-type':'application/json'},body:JSON.stringify({name:''.padStart(100000,'A')})}).then(res=>{console.log(res)}) 
在控制台中可以看出,打印buffer.length出现了2次,因为传值不是一下传过来的,因为tcp是分包传输。
➜ 1.6 git:(master) ✗ nodemon ./index.js
[nodemon] 2.0.4
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node ./index.js`
启动成功
buffer 64773
buffer 35238
contentType application/json
2
3
4
5
6
7
8
9
10
- 修改 PUT /product/:id
app.put('/product/:id',(req,res)=>{
console.log(req.params.id)
res.sendStatus(204)
})
2
3
4
- 删除 DELETE /product/:id
app.delete('/product/:id',(req,res)=>{
console.log(req.params.id)
res.sendStatus(204)
})
2
3
4
# 1.6.2 跳转Header和3xx状态码
# 🍅 实战-重定向观察
- 观察下列重定向行为的区别
- 301、302、303、307
- 301
当访问http://localhost:3000/301时候,浏览器会跳转到http://localhost:3000/def;跳转是浏览器的行为。
const express = require('express')
const app = express()
// 遵守规范有利于网站的seo,不能随便用301,浏览器会有缓存
app.get('/301',(req,res)=>{
res.redirect(301,'/def')
})
app.get('/def',(req,res)=>{
res.send('THIS IS DEF(get)')
})
app.listen(3000,()=>{})
2
3
4
5
6
7
8
9
10
11
12
- 302、303、307
const express = require('express')
const app = express()
// 302、303 post请求会重定向到get请求
app.post('/302',(req,res)=>{
res.redirect(303,'/def')
})
app.post('/303',(req,res)=>{
res.redirect(303,'/def')
})
app.get('/def',(req,res)=>{
res.send('THIS IS DEF(get)')
})
// 307 post请求,会重定向到post请求
app.post('/307',(req,res)=>{
res.redirect(307,'/def')
})
app.post('/def',(req,res)=>{
res.send('THIS IS DEF(307post)')
})
app.listen(3000,()=>{})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 1.6.3 实战-错误处理
- 为下列场景返回不同的错误码
- 用户没有登录
- 服务器报错
- 内容没有找到
- 不支持POST请求
const express = require('express')
const app = express()
// 用户没有登录
app.post('/test',(req,res)=>{
res.sendStatus(404)
})
// 500服务端抛错,会自定帮你做
app.post('/test',(req,res)=>{
throw "Error"
})
// 502网管错误,一般不自己指定
app.post('/test',(req,res)=>{
res.sendStatus(502)
})
// 找不到资源,一般找不到资源框架会帮去返回404
app.post('/test',(req,res)=>{
res.sendStatus(404)
})
app.listen(3000,()=>{})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 1.7 加密和HTTP证书
# 1.7.1 对称加密和非对称加密
# 🍅 明文传输
如果2个人对话,本来就是私密的,当然不想让三个人看见;如果小区有交换机,小区的工人人员就可以看报文,可能就会动起了坏心思。
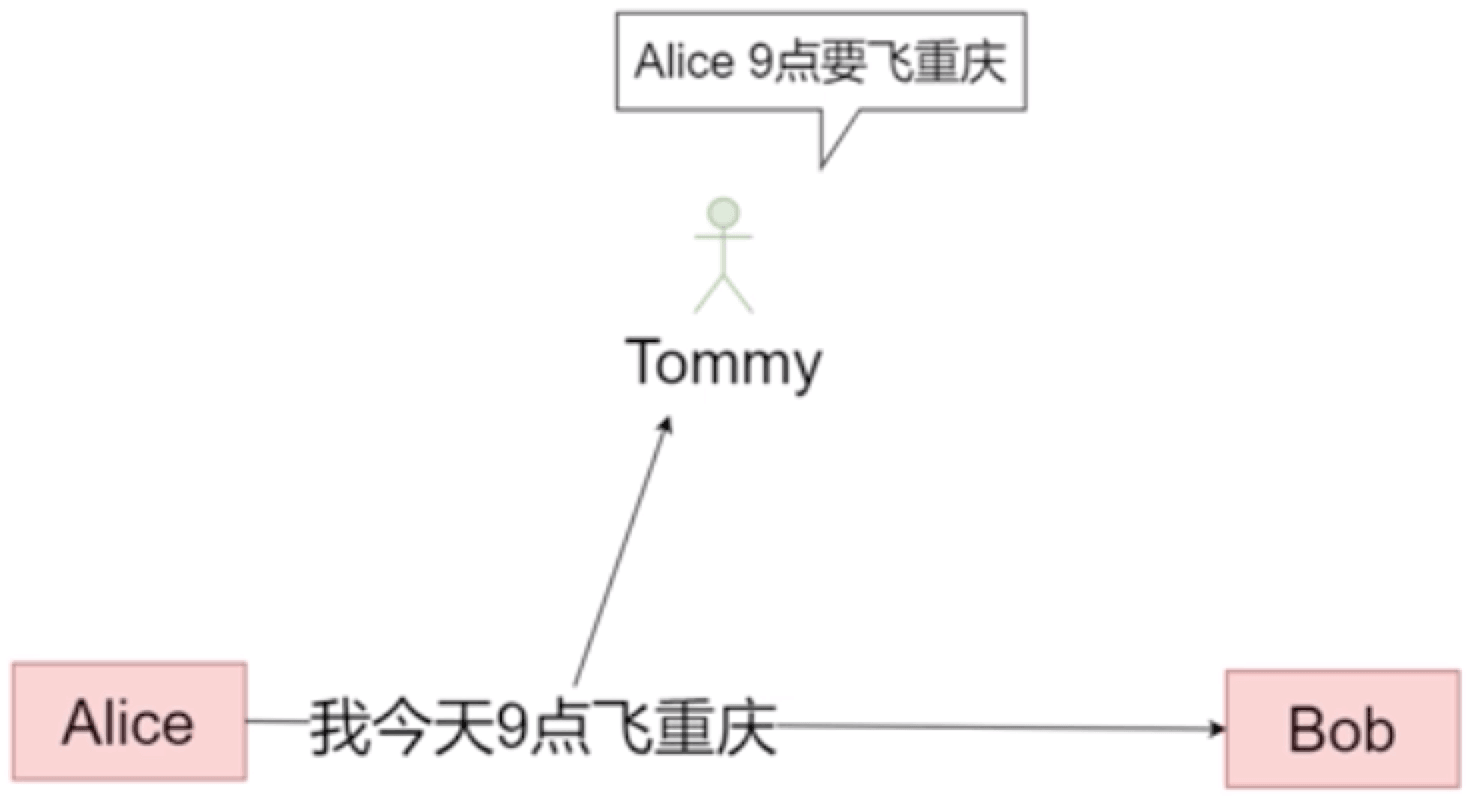
# 🍅 加密
给Alice传的发出内容进行加密,Bob这边在进行解密;加密解密也没回绝对安全;这样给破解人增加了难度。
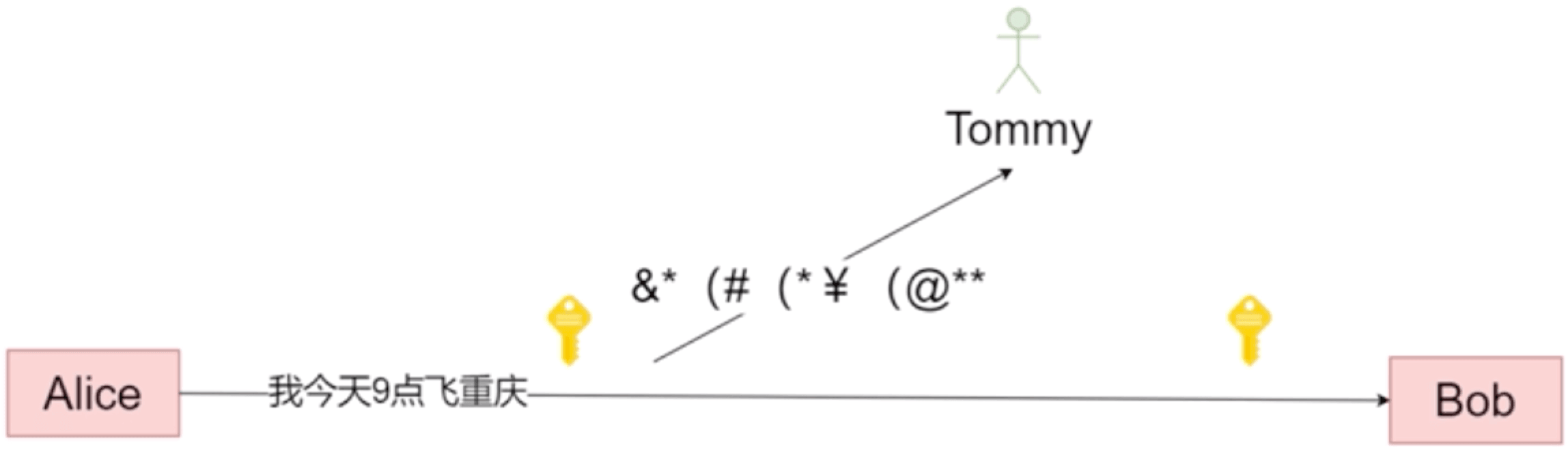
# 🍅 什么是加密
将明文信息变成不可读的密文内容,只有拥有解密方法的对象才能够将密闻还原成加密前的内容
下面的例子就是隔3个拿一个字符,从而达到给明文加密

# 🍅 加密方法/解密方法
- 计算机中,加密方法和解密方法,可以描述为一段程序,我们称作加密/解密算法
- 加密有时候会对暗号,比如上一个例子中每次跳过3个字符,[3]就是一个暗号,我们称作密钥
# 🍅 对称加密/非对称加密
- 加密和解密的暗号(秘钥)相同,我们称为对称加密
- 加密和解密的暗号(秘匙)不同,我们称为非对称加密
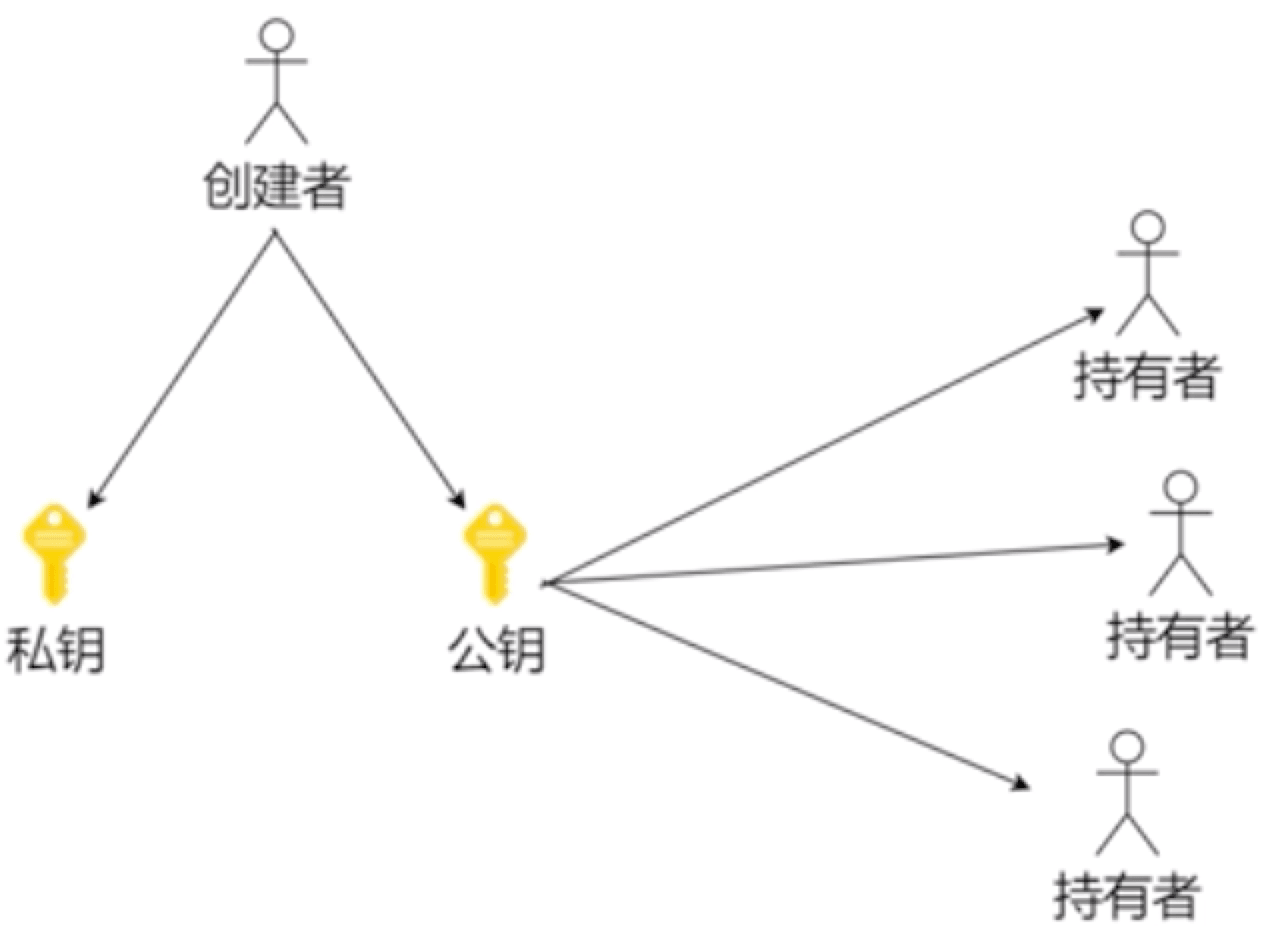
# 🍅 非对称加密(秘钥对)
- 创建者创建一个秘钥对(分成公钥和私钥)
- 公钥加密必须私钥解密
- 私钥加密必须公钥解密
- 创建者保留私钥,公钥向外界公开
# 1.7.2 信任体系
# 🍅 证书体系
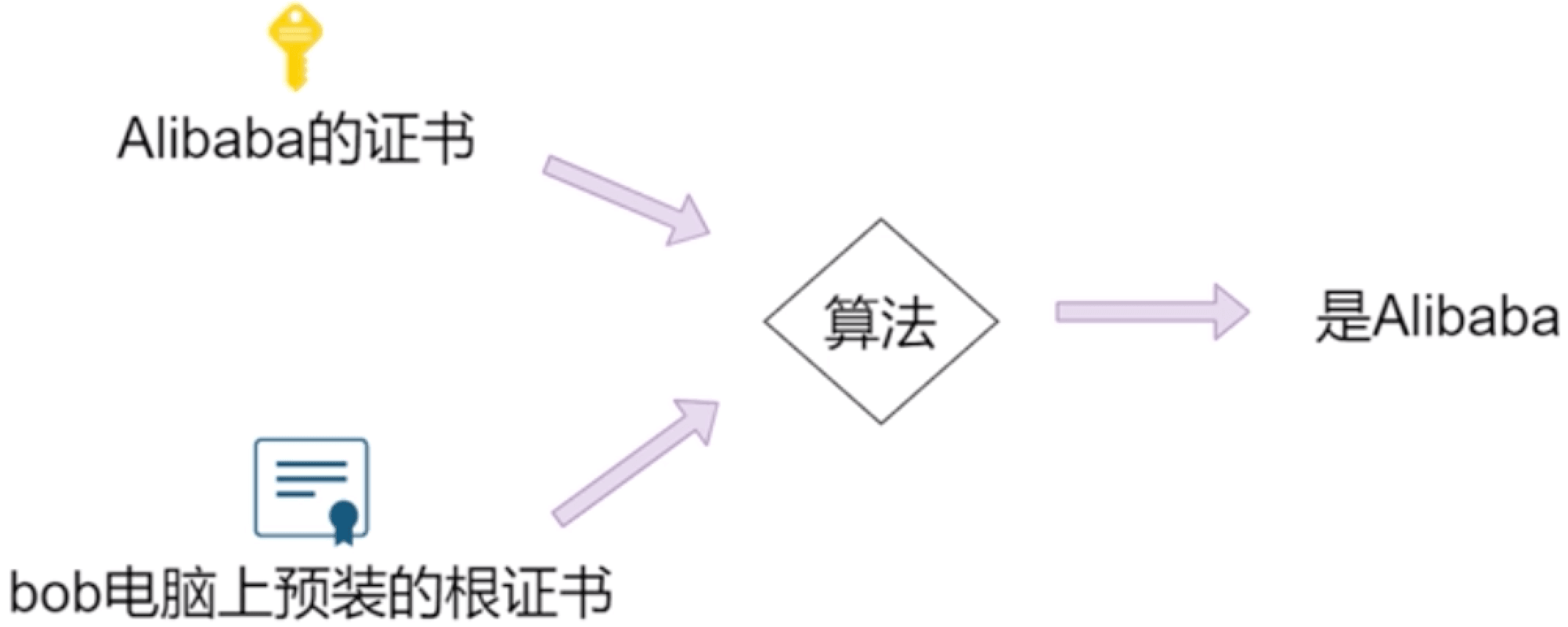
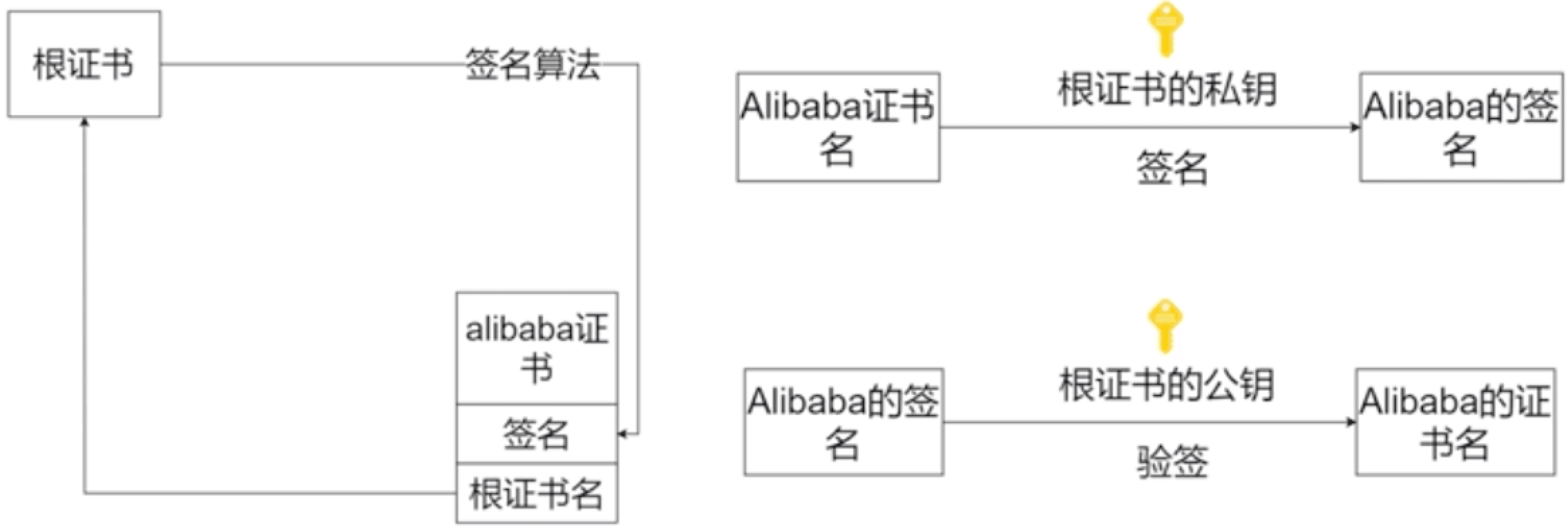
# 🍅 算法如何验证证书就是Alibaba
Alibaba向第三方证书机构申请证书,第三方机构用根证书的私钥给Ailibaba证书签名;然后可以用根证书的公钥进行验证签名是不是alibaba的证书。
# 1.7.3 算法种类介绍
- DES (Data Encryption Standard)
- 1970 IMB提出的对称加密算法
- 可暴力破解
- AES (Advanced Encryption Standard)
- 2001年美国国家标准于技术研究院发布的对称加密算法
- 可旁道攻击
- RSA(Rivest-Shamir-Adleman)
- 1997年发布的非对称加密算法
# 🍅 对称 VS 非对称
- 非对称加密安全性更好
- 对称加密计算速度更快
- 通常混合使用(利用非对称加密协商密钥,然后进行对称加密,https也是混合使用,不是一种加密用到底的)
# 1.7.4 HTTPS工作原理
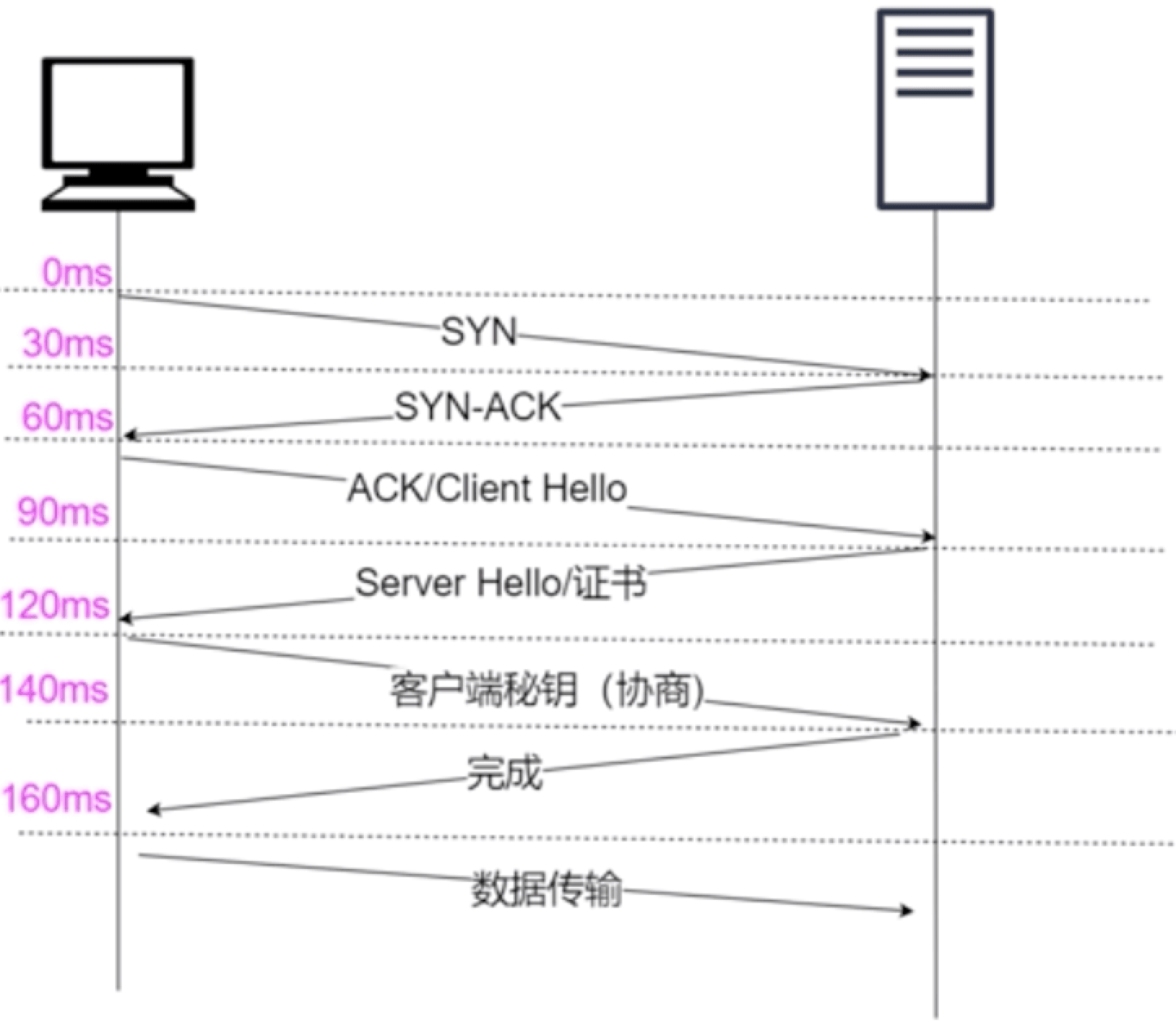
假如有30ms网络延迟,假如用https发送一条数据,服务端收到到确认成功,最少使用多少时间?
需要190ms,服务端收到后还会发送还会发送一个ack
# 1.8 UDP vs TCP,HTTP vs HTTPS
# 1.8.1 UDP
比TCP节省网络资源和迅速
- 不需要建立连接(延迟更低)
- 封包体积更小 (传输入速度快)
- 不关心数据顺序(不需要序号和ACK,传输快速)
- 不保证数据不丢失
# 思考
没有虚拟连接、不校验数据、不保证顺序、没有收到不重复---是不是意味着不安全、不可靠?
UDP自由度跟高
- 需要用户程序在应用层定义类似的机制
- TCP面向流(API接收流)、UDP面向消息(API接收数据包)
场景不同
- 模糊:文件&文本、多媒体
- TCP:远程控制
- UDP:DNS查询
# 1.8.2 HTTP2.0 目标
- 多个请求多路复用
- 防止对头阻塞
- 压缩HTTP头部
- 服务端推送
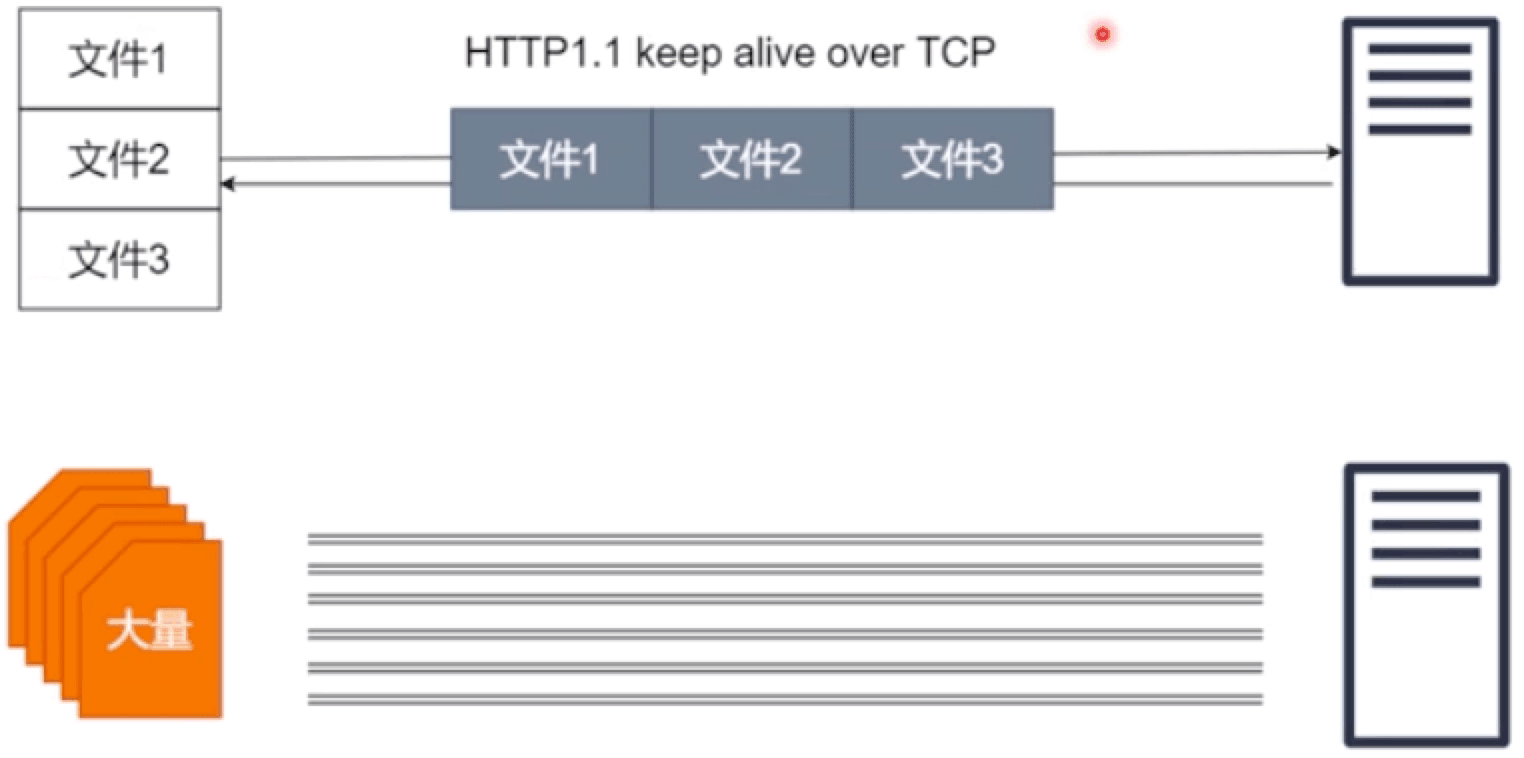
# 🍅 HTTP 1.1 排队问题
HTTP 1.1多个文件共用一个TCP,这样可以减少tcp握手,这样3个文件就不用握手9次了,不过这样请求文件需要排队,请求和返回都需要排队, 如果第一个文件响应慢,会阻塞后面的文件,这样就产生了对头的等待问题。
有的网站可能会有很多文件,浏览器处于对机器性能的考虑,它不可能让你无限制的发请求建连接,因为建立连接需要占用资源,浏览器不想把用户的网络资源都占用了,所以浏览器最多会建立6个tcp连接;如果有上百个文件可能都需要排队,http2.0正在解决这个问题。
# 🍅 HTTP 2.0
- 多路复用
http1.1是一个请求过去,一个请求返回来,然后在进行下一个请求;其实是在排队的。http2.0发现2个请求比较靠近,把2个请求打包成一个请求发过去;也就是说把几个请求打包成一个小块去请求,并行发送;即使一个阻塞了,另一个还能回来,可以并行的出去也可以并行的回来;假如第一个请求需要0.8秒,第二个第三个各需要0.5秒;那么http2.0可以在0.8秒内把这3个一起去请求,这样只需0.8秒,即使一个阻塞了也不影响其他的返回。
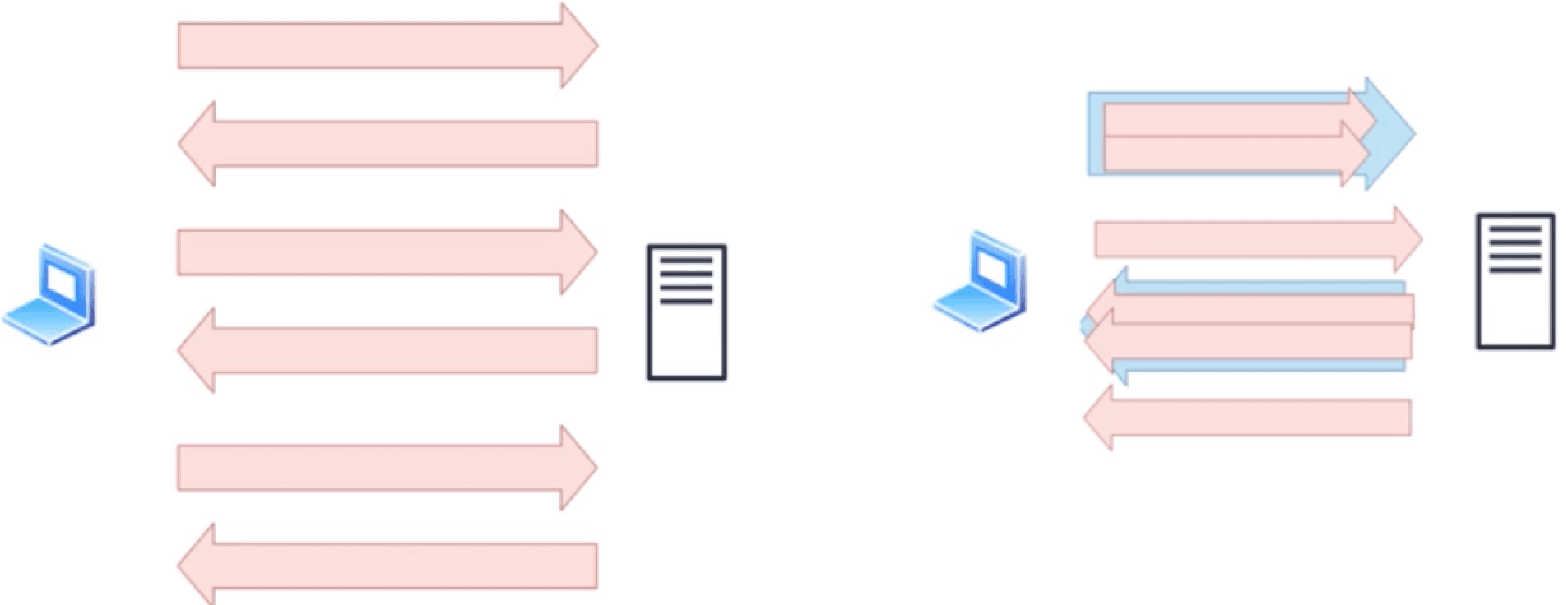
- 防止对头阻塞
http1.1如果第一个文件阻塞,第二个文件也就阻塞了。

http2.0的解决,把3个请求打包成一个小块发送过去,即使第一个阻塞了,后面2个也可以回来;相当于3个文件同时请求,就看谁先回来谁后回来,阻塞的可能就后回来,对带宽的利用是最高的;但没有解决TCP的对头阻塞,如果TCP发过去的一个分包发丢了,他会重新发一次;http2.0的解决了大文件的阻塞。
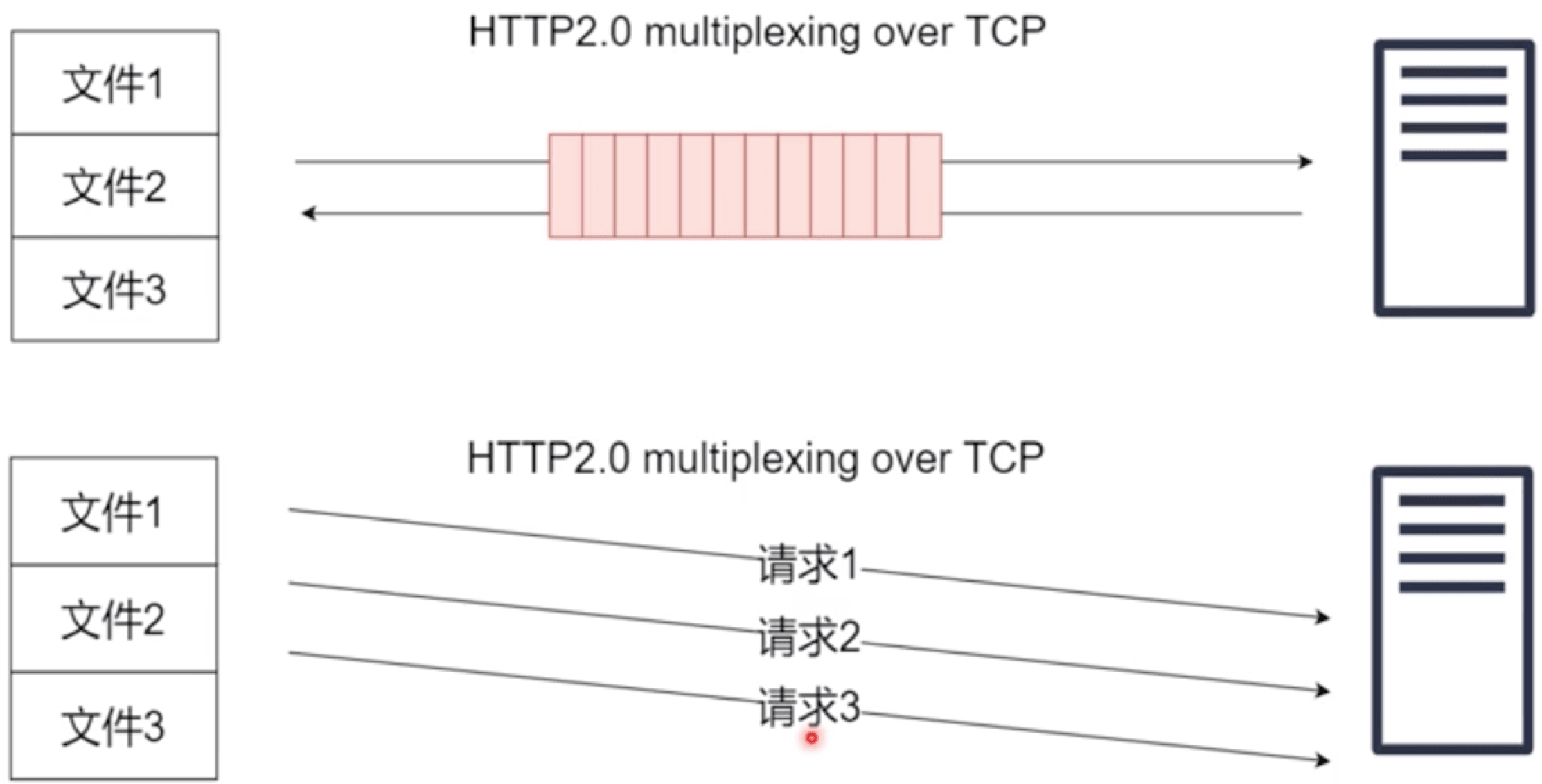
一个分包请求3个文件,即使第一个阻塞了,第二个也能返回
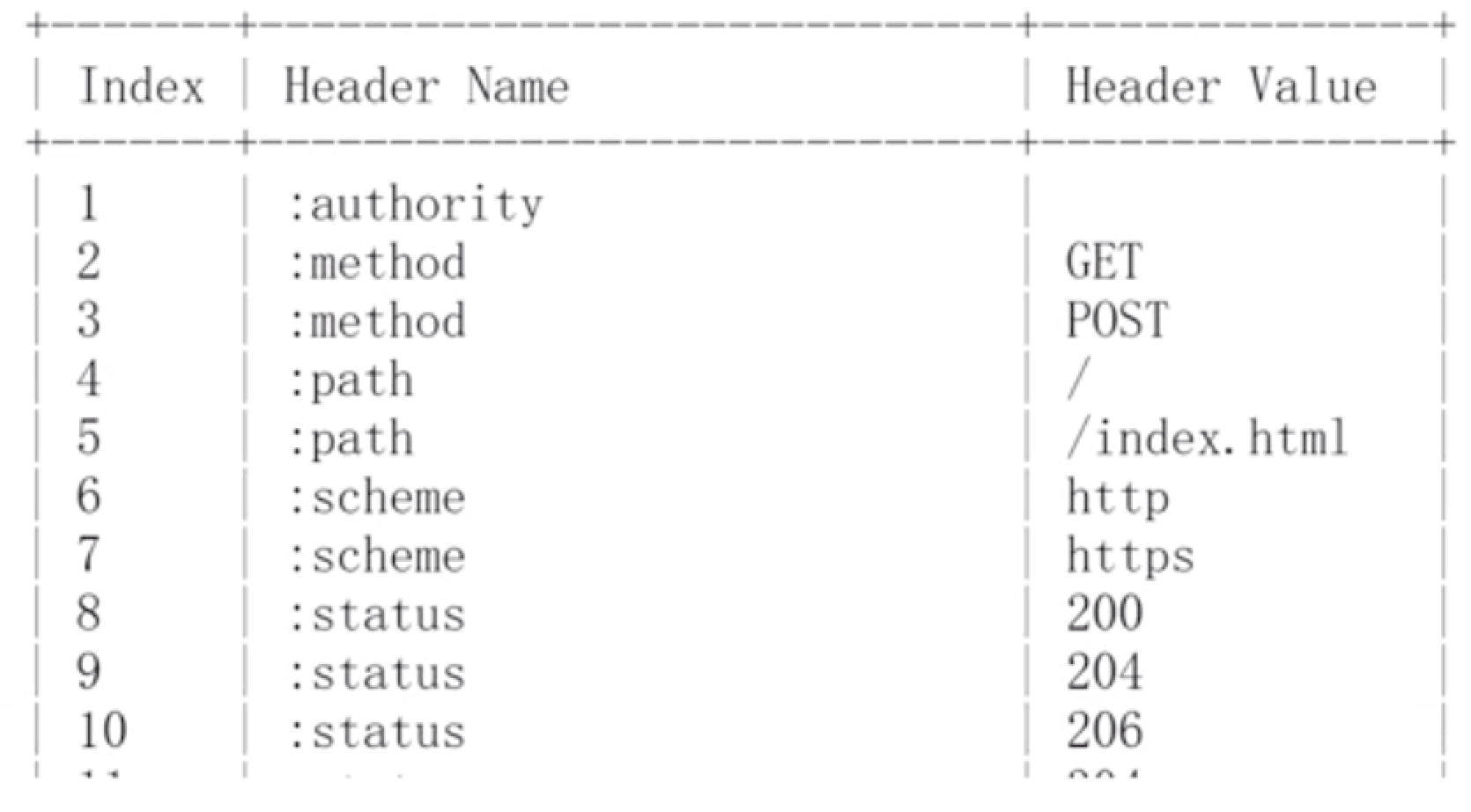
- 压缩头部
- HPACK技术
例如:METHOD GET 用2表示,就是我用2去表示METHOD GET,这样不就小了,这样压缩比率非常大,可以参考下面表代表Header压缩后的字符。
- 服务端推送
我们现在的网站是先请求一个html,然后加载这个html,如果这个html有js文件和css文件,在去请求js和css;有没有可能html、js、css一起推送过来,这样是不是快很多。
当也有一个问题,现在页面主要是js渲染,那么js的先后顺序影响了页面的渲染;那么服务端推送也就存在问题了。
# 1.8.3 HTTP3.0
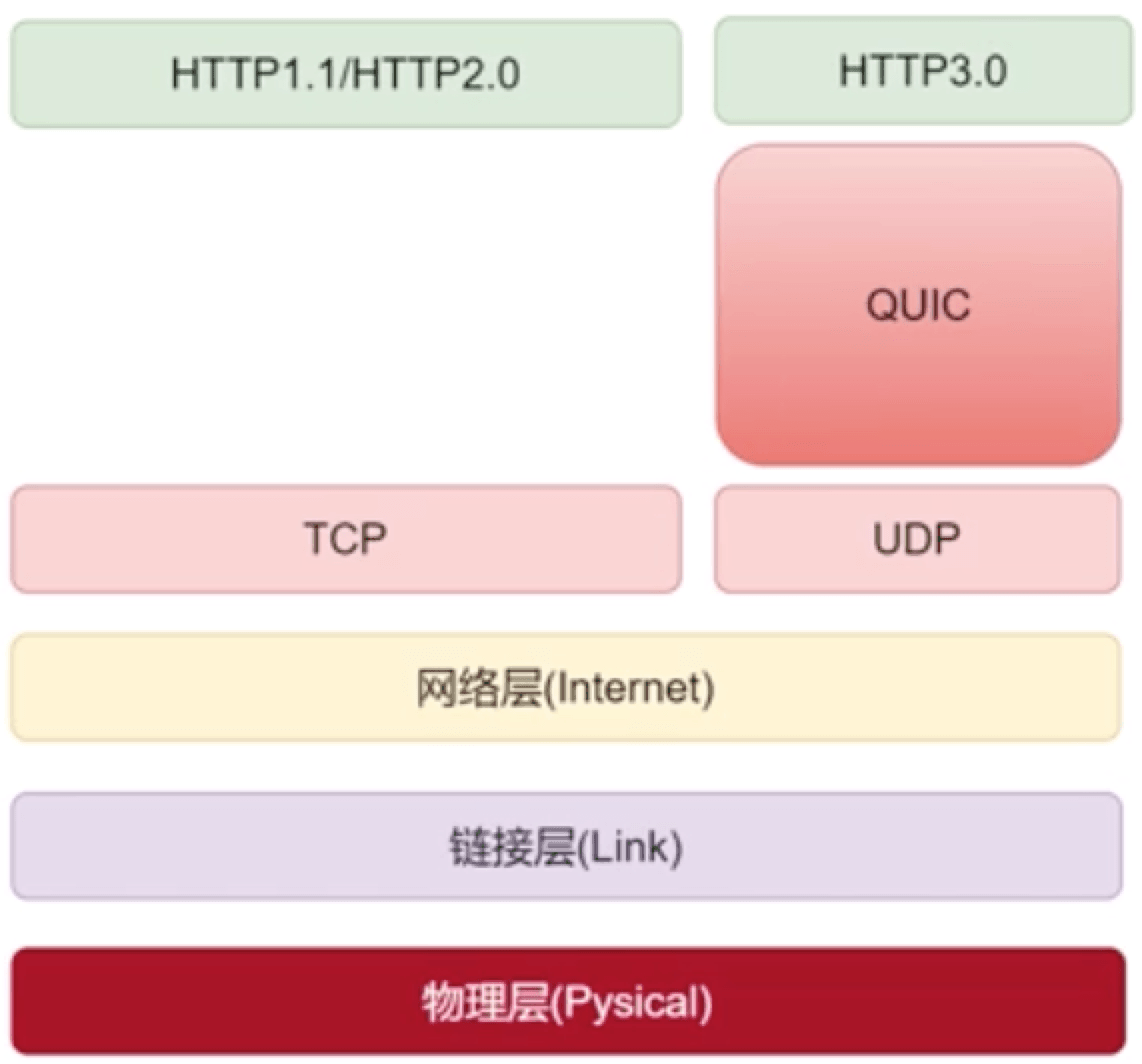
http3.0现在还属于一个实验阶段,上面是一个体系图,理解了TCP和UDP的关系,就会理解为什么有个3.0。
从网络层(ip)->链接层->物理层这里是基本不变的,传输层是TCP或UDP,在这个TCP之上构建了HTTP1.1/HTTTP2.0的体系,0.9、1.0大家已经不用了,现在基本都是2.0。
3.0直接把TCP换成UDP了,换成UDP后就出问题了,可靠性和安全性上出了问题,那么就自己做一层,这个叫QUIC,就是快的意思;谷歌的作品,这个谷歌说给http提高了很大的一部分空间,因为TCP到UDP本来就有很大的性能差距。
http1.1/http2.0中间还有一个加密层,还要对数据的压缩,QUIC自己层承担了这部分工作,优化做的非常足,所以速度很快;3.0不再改协议了,也没有这么多的概念,它是整个层重写了,是基于UDP的,因为要保证可靠性,它是基于文件传输做的重写;文本传输做的重写,这就是3.0。
# 总结
- UDP把自由度给了用户,使用的人少,TCP自由度低,用的人多。
- HTTP2.0/HTTP3.0都兼容HTTP1.1